DataFrame - 데이터 그룹핑하기
통계자료에서 많이 사용한다.
그룹핑 시켜서 합을 도출하거나 혹은 평균값을 구하거나 등
import numpy as np
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
np.random.seed(100)
df = DataFrame({
'Gender':['Female','Male','Female','Male','Female','Male','Female','Female'],
'Smoking':['Smoker', 'Smoker', 'Smoker', 'Non-Smoker','Non-Smoker','Non-Smoker','Non-Smoker','Smoker'],
'JumpHeight':np.random.randint(10,100,8),
'LungCapa':np.random.randint(10,100,8)
})
df # 전체데이터

# 그룹핑 → groupby()
전체데이터를 세분화 : 그룹핑
groupby 함수로 데이터를 그룹핑하면 DataFrameGroupBy 객체가 리턴된다.
↑이 상태로는 아무것도 하지 못함
집계함수를 이용해야 결과값을 리턴받을 수 있다.
# 그룹핑 -> groupby()
# 전체데이터를 세분화 : 그룹핑
# groupby 함수로 데이터를 그룹핑하면 DataFrameGroupBy 객체가 리턴된다.
# ↑이 상태로는 아무것도 못한다.
# 집계함수를 이용해야 결과값을 리턴받을 수 있다.
df.groupby('Gender') # 객체리턴
==========================================
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001B9A8F89B50>
# sum ()
df.groupby('Gender').sum()
#Smoking 리턴 안된 이유는 numeric data가 아니라서 sum적용이 안된다.
# max ()
df.groupby('Gender').max()
# 성별로 나누고 다시 흡연여부로 나눔 -> sum()
# 성별로 나누고 다시 흡연여부로 나눔 -> sum()
df.groupby(['Gender','Smoking']).sum() # dataframe로 리턴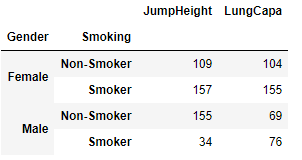
# 특정한 컬럼(폐활량, 성별)값에 대해서만 그룹핑
# 특정한 컬럼(폐활량, 성별)값에 대해서만 그룹핑
df.groupby('Gender')['LungCapa'].max() # Series로 리턴
df.groupby('Gender')['LungCapa'].agg('max') # 동일한결과
====================================================
Gender
Female 70
Male 76
Name: LungCapa, dtype: int32
DataFrame 반환
# DataFrame 반환
df.groupby('Gender')[['LungCapa']].max()
df.groupby('Gender')[['LungCapa']].agg('max') # 위랑 같음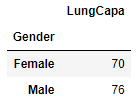
df.groupby('Gender')['LungCapa'].agg(['max'])
## agg는 aggregation 이라는 뜻으로 여러개의 함수를 동시에 사용해서 그룹핑 가능하다.
df.groupby('Gender')['LungCapa'].agg(['sum','max','count'])
실전데이터 응용하기
tipdf = pd.read_csv('../data/tips.csv')
tipdf.head(1)
# 1. 요일별로 그룹핑하고 conut() 함수를 적용
# 1. 요일별로 그룹핑하고 conut() 함수를 적용
tipdf.groupby('day').count()
# 2. 요일별 팁의 평균
시리즈반환
# 2. 요일별 팁의 평균
tipdf.groupby('day')['tip'].mean() # 시리즈반환
===========================================
day
Fri 2.734737
Sat 2.993103
Sun 3.255132
Thur 2.771452
Name: tip, dtype: float64
데이터 프레임 반환
tipdf.groupby('day')[['tip']].mean()
# 2-1. 위의 값과 동일
day_group = tipdf.groupby('day')
day_group[['tip']].mean()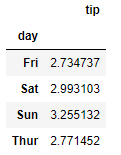
내림차순 정렬
# 2-2 내림차순 정렬
day_group['tip'].mean().sort_values(ascending=False)
=====================================
day
Sun 3.255132
Sat 2.993103
Thur 2.771452
Fri 2.734737
Name: tip, dtype: float64
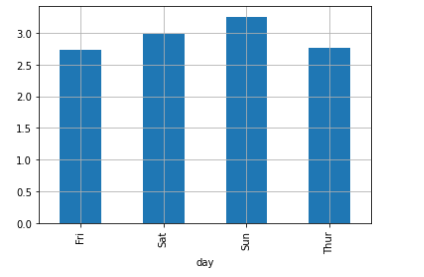
시각화
# 2-3 시각화
day_group['tip'].mean().plot(kind = 'bar', grid = True)
plt.show()
이중으로 그룹핑하기
# 1. 성별로 먼저 그룹핑하고, 나중에 다시 흡연여부로 그룹핑,
# 통계함수는 mean()
double_group = tipdf.groupby(by=['sex','smoker'])
double_group.mean()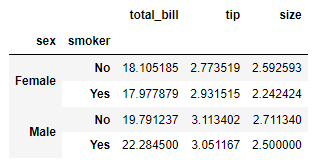
double_group.mean().plot(kind = 'bar')
plt.show()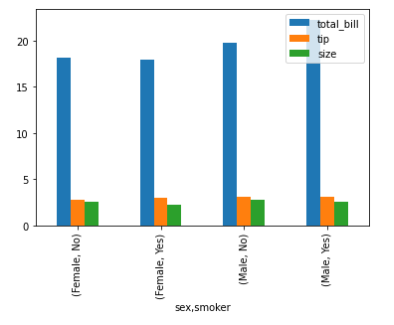
알아두어야 할 함수
- unique - DISTINCT
- describe - 4분위(25%, 50% 75% 100%) 함수
- value_counts - 해당 컬럼에서 그 값이 몇 번 나왔는지 확인 가능, 빈도수 확인하는 함수
- apply - 판다스에서 내가 직접 함수 정의할 때 적용
df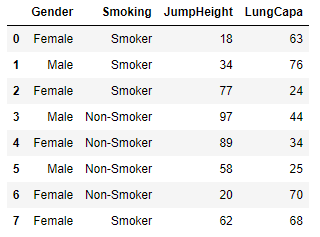
1. unique ( )
#1. unique ()
df['Gender'].unique()
=================
array(['Female', 'Male'], dtype=object)
2. describe()
#2. describe () :: 데이터에 대한 간단한 설명 -> 간단한 통계
df.describe()
3. value_counts()
# 3.value_counts() :: 빈도수확인, 해당 컬럼에서 특정값이 몇번 나왔는지
df['Smoking'].value_counts()
=============================================
Smoker 4
Non-Smoker 4
Name: Smoking, dtype: int64
4. apply
# 4. apply
'''
판다스에서는 여러가지 통계함수를 제공하고 있지만
내가 직접 함수를 정의해서 사용해야 하는 경우가 발생
사용자 정의 함수
def add(x):
return x + 12
이렇게 만든 함수를 가져다 사용할 때 apply를 적용함
'''
def add(x):
return x + 12
df[['LungCapa']].apply(add)
df[['LungCapa']].agg(add) # apply 처럼 agg 에 적용 가능
Pivot Tables
피벗함수는 DataFrame의 데이터를 ReShape 하는 강력한 방법
여러 컬럼을 index, values, columns 값으로 사용할 수 있다.
import numpy as np
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
data = {
"도시": ["서울", "서울", "서울", "부산", "부산", "부산", "인천", "인천"],
"연도": ["2015", "2010", "2005", "2015", "2010", "2005", "2015", "2010"],
"인구": [9904312, 9631482, 9762546, 3448737, 3393191, 3512547, 2890451, 263203],
"지역": ["수도권", "수도권", "수도권", "경상권", "경상권", "경상권", "수도권", "수도권"]
}
df1 = DataFrame(data)
df1
# 매개변수 (위치매개변수 : 위치, 순서)
(키워드매개변수 : 키워드 이름)
'''
매개변수 (위치매개변수 : 위치, 순서)
(키워드매개변수 : 키워드 이름)
values=None,
index=None,
columns=None,
aggfunc='mean', -> 평균값 디폴트
'''
# df1.pivot_table?
df1.pivot_table(values = '인구', index = '도시', columns = '연도') #키워드매개변수
df1.pivot_table('인구','도시','연도') # 위치매개변수
df1.pivot_table('인구', columns ='연도', index = '도시') # 섞어서 사용해도 가능하다
df1.pivot_table('인구', columns ='연도', index = '도시', margins = True)

df1['인구'].mean() #margins
=====================================
5350808.625
df1.pivot_table('인구', index=['연도','도시'])
# 연도별, 도시별 인구수 -> index 의 역할은 세분화!
# pivot_table = groupby 와 같은 역할

'|Playdata_study > Python' 카테고리의 다른 글
| 210727_시각화(Matplot, Seaborn) (0) | 2021.07.27 |
|---|---|
| 210726_Pivot Tables 2 (0) | 2021.07.26 |
| 210723_Concat,Merge (0) | 2021.07.24 |
| 210722_NaN (누락데이터) (0) | 2021.07.23 |
| 210722_Pandas (DataFrame) (0) | 2021.07.23 |




댓글