복습! (list 객체를 txt파일로 저장)
def Test():
listdata = [2, 2, 1, 3, 8, 5, 7]; result = sorted(listdata) #리스트의 요소를 정렬한다.
print(result) #[1,2,2,3,5,7,8]
f = open("c:\\data\\mydata11.txt", "w") #mydata11.txt를 생성하겠다
f.write(str(result)) #result에 있는 내용을 mydata11.txt로 생성한다.
f.close() #result 에 있는 내용을 문자로 변환 해야한다.
def Test01(): #아래의 리스트를 mydata12.txt로 저장하시오!
listdata2 = ['a','b','c','d','e','f','g']
result = sorted(listdata2); print(result);
f = open("c:\\data\\mydata12.txt", "w")
f.write(str(result)); f.close()
def Test02():
data = [] #data라는 비어있는 리스트 생성
while True: #무한루프를 수행
text = input('저장할 내용을 입력하세요')
if text == '': # text에 아무것도 입력하지 않으면
break #break 문을 실행해서 무한루프를 종료
data.append(text + '\n') #text가 엔터와 함께 data 리스트에 append
f = open('c:\\data\\mydata13.txt','w' ) #mydata13.txt 를 생성하겠다.
f.writelines(data); f.close() #data 리스트의 내용을 mydata13.txt에 저장하겠다.<결과>

저장할 내용을 입력하세요 안녕하세요?
저장할 내용을 입력하세요
저장할 내용을 입력하세요
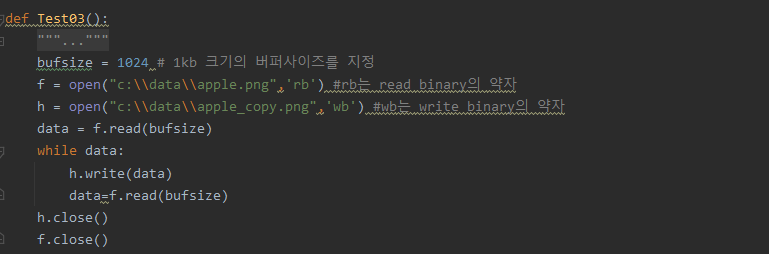
Process finished with exit code 0바이너리 파일 복사하기
(read, write)
이미지나 동영상도 파이썬으로 복사 붙여넣기를 할 수 있다.
이미지나 동영상을 복사 붙여넣기 할때는 파일의 크기가 크므로 한번에 읽어들일 수는 없고 일부분만 일정한 크기도 읽으면서 복사 붙여넣기를 한다.

웹 스크롤링
# 예제 : url의 게시판의 전체의 글을 모두 크롤링해서 날짜와 본문내용 가져오기


# 예제 : url의 게시판의 전체의 글을 모두 크롤링해서 날짜와 본문내용 가져온 후 txt파일에 저장

# 1. url에서 = 인공지능으로 검색해서 패턴보기
2. 상세기사 url 리스트에 담는 d_scroll()를 만든다
3. 상세기사 url 로 기사 본문을 스크롤링 하는 j_detail_scroll()
4. j_detail_scroll()함수에서 j_scroll()를 호출한 후 상세기사 url 받아서 본문기사 params에 담자.

# from collections import Counter
: 데이터의 개수가 많은 순으로 정렬된 배열을 리턴하는 most_common이라는 메서드 제공
# 게시판에서 다운로드 받았던 내용 중 가장 많이 나오는 단어(어절) 구하기

웹 스크롤링한 데이터를 분석하는 방법
1. 감정분석 : 회사에 신제품 출시되었을때의 소비자 반응
2. 사회 현상을 파악하고자 할때 (국가)
3. 인공지능 상담원을 만들기 위한 자연어 처리 학습데이터로 웹 스크롤링한 데이터를 활용
4. 인공지능의 눈이라고 할 수 있는 딥러닝의 CNN의 신경망의 학습 데이터로 이미지 데이터가 활용
데이터 구조적 관점 3가지
1. 정형데이터 : 정형화된 스키마구조, DBMS에 저장할 수 있는 구조
(Oracle, Mysql. MSsql)
2. 반정형 데이터 : 데이터 내부의 데이터 구조에 대한 메타정보가 포함된 구조의 데이터
html, xml, json
3. 비정형 데이터 : 웹 스크롤링 기술로 수집해서 모든 데이터
텍스트, 이미지, 동영상
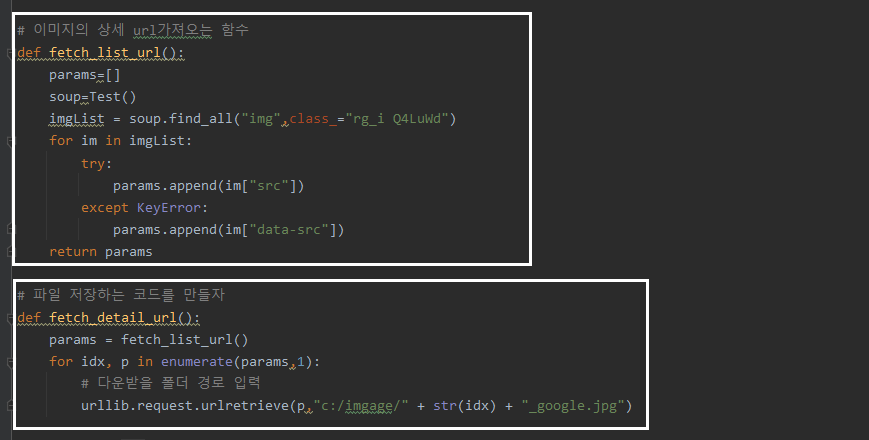
웹의 있는 사진을 스크롤링 (ex, 구글이미지)
딥러닝기술?
1. CNN : 인공지능의 눈 → 이미지
2. RNN : 인공지능의 입과 귀 → 자연어 처리를 위한 문장들
→ 셀리니움을 써서 마치 손으로 클릭해서 이미지를 정하듯이 저장되는 기술로 컴퓨터를 시켜서 자동화 시키는 방법으로 클로링한다.
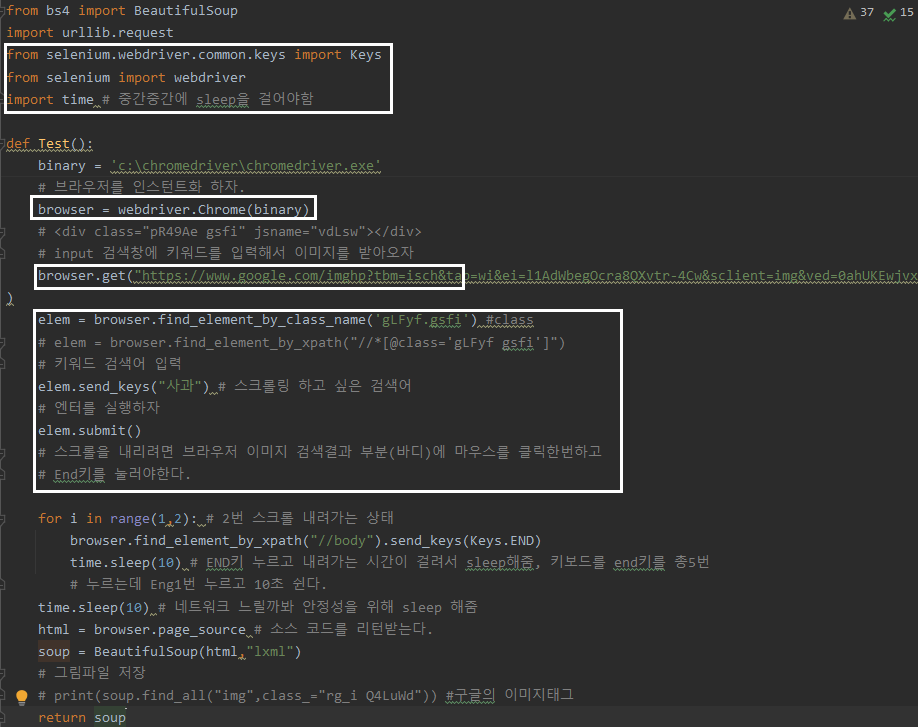
Selenium
# from bs4 import BeautifulSoup
: 파이썬 코드를 복잡하게 작성하지 않아도 편하게 웹 크롤링을 할 수 있도록 여러가지 함수를 제공하는 모듈
# import urllib.request
: 웹 상의 url을 파이썬이 인식할 수 있도록 해주는 모듈
# from selenium.webdriver.common.keys import Keys
from selenium import webdriver
: 브라우저에 맞는 webdriver를 다운받아 해당파일이 있는곳을 PATH 추가
# browser = webdriver.Chrome() → 변수 = webdriver.브라우저명()
browser.get ("http:// ~~")
: 특정 페이지 열기
# elem = browser.find_element_by_class_name
: element가 찾기 쉽게 id나, class, name 등으로 작성되어 있다면
find_element_by_id() 혹은 find_element_by_name() 등으로 찾을 수 있다.
# elem.send_keys
: element가 input과 같은 입력 가능한 요소라면 send_key()로 입력 가능
'|Playdata_study > Python' 카테고리의 다른 글
| 210721_Pandas(Series, Matplot) (0) | 2021.07.23 |
|---|---|
| 210720_Numpy (array, random, 인덱싱, 슬라이싱) (0) | 2021.07.20 |
| 210511_웹 크롤링 (0) | 2021.05.11 |
| 210510_Json 구현 및 웹 서비스 (0) | 2021.05.10 |
| 210507_모듈 활용 및 csv (0) | 2021.05.07 |



댓글