Hadoop Echo System
: 사용목적에 따라 선택해서 사용하면 된다.
Pig - 내부에서 데이터 관리
Hive - 데이터웨어하우징(DW)용 솔루션 (정형 데이터를 한 대 이상의 클러스터를 묶어 관리)
데이터 수집, 저장 역할이 많으면 사용
하둡 안에 Hive 라는 서버를 만들어서 클라이언트 관리한다.
(server, client)
데이터를 크게 관리한다는 측면에서 다른 에코시스템과 다르다
Spark - 실시간 데이터를 필요하면 바로 당겨오거나 거쳐올 수 있다.
HDFS
- 대규모 데이터를 저장하고 배치를 저장할 때 호스트가 연결 되어있는 상태에서 데이터를 업로드 하게된다.
- Master = name노드와 같다, name노드는 모든 메타데이터, 슬레이브 설정을 기록하는 역할
root밑에 data방을 만들어 hadoop, ~~ name - 네임방은 기록지가 달라진다.
- Slave = data노드와 같다.
🔆 중요!!!
Hadoop : Core, HDFS , Yarn, Map/Reduce
MapReduce Tutorial
아래의 Hadoop docs를 참고해 MapReduce를 활용한 WordCount를 활용 하려고 한다.
1. Maven Project 만들기 → Create a simple project → WordCount2 이름을 그대로 넣자
2. pom.xml 에 hadoop 관련 라이브러리의 의존 관계를 넣는다.
<dependencies></dependencies> 부분을 추가하고 저장하면
자동으로 Maven Dependencies 라이브러리가 생성된다. (주석부분 제외)
3. package 가 만들어 지면 export 하여 .jar 파일을 만든 후 공용 폴더로 전송하자 (리눅스/hadoop 에서 사용할 예정)
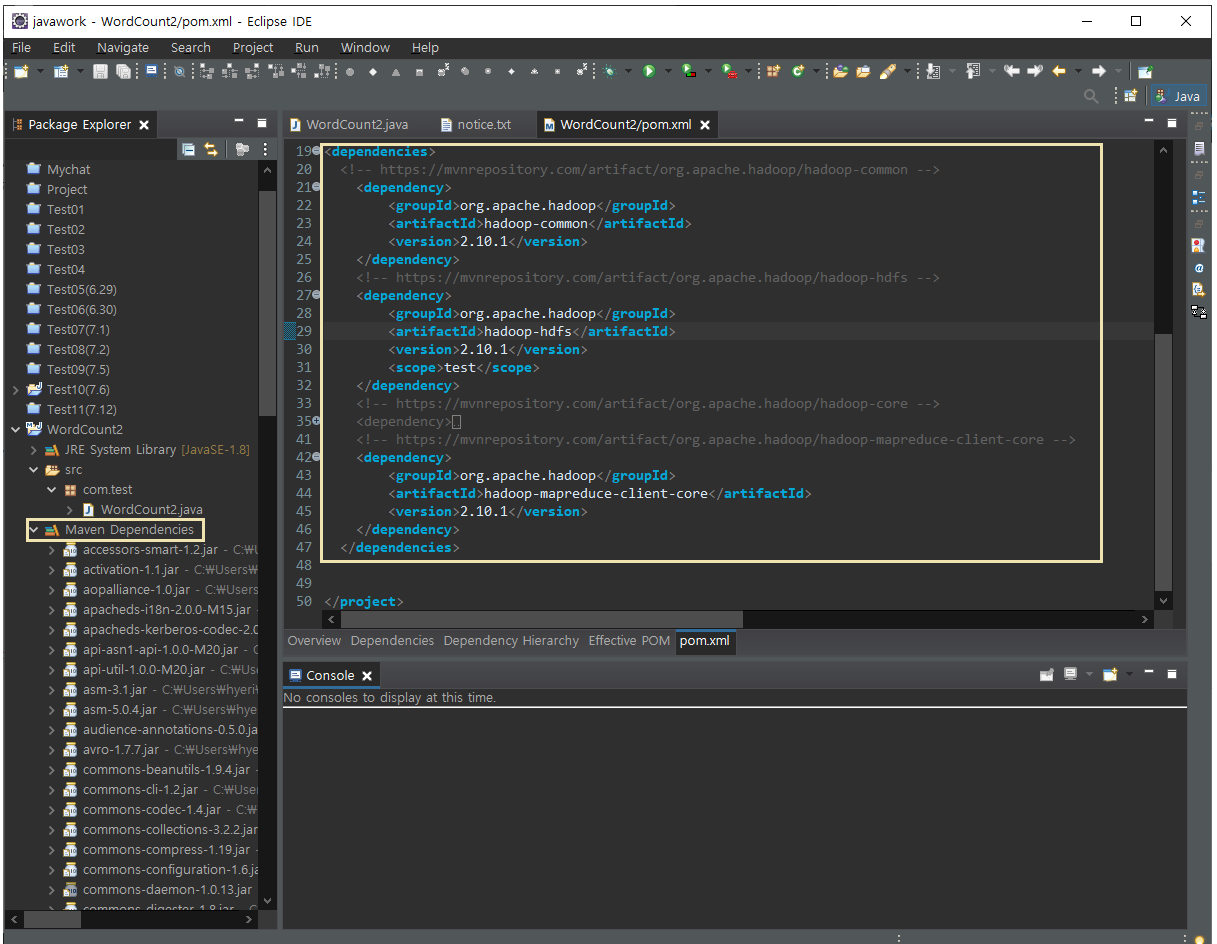
[pom.xml]
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>WordCount2</groupId>
<artifactId>WordCount2</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.10.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.10.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core -->
<!--
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
-->
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.10.1</version>
</dependency>
</dependencies>
</project>
[WordCount2 class]
package com.test;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.StringUtils;
public class WordCount2 {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ //object,test - input , text, Intwritable - output
static enum CountersEnum { // 상수 기능을 구현하는
INPUT_WORDS
}
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private boolean caseSensitive;
private Set<String> patternsToSkip = new HashSet<String>();
private Configuration conf;
private BufferedReader fis;
//hdfs URL 검증 메소드
@Override
public void setup(Context context) throws IOException,
InterruptedException {
conf = context.getConfiguration();
caseSensitive = conf.getBoolean("wordcount.case.sensitive", true);
if (conf.getBoolean("wordcount.skip.patterns", false)) {
URI[] patternsURIs = Job.getInstance(conf).getCacheFiles();
for (URI patternsURI : patternsURIs) {
Path patternsPath = new Path(patternsURI.getPath());
String patternsFileName = patternsPath.getName().toString();
parseSkipFile(patternsFileName);
}
}
}
//user_method
private void parseSkipFile(String fileName) {
try {
fis = new BufferedReader(new FileReader(fileName));
String pattern = null;
while ((pattern = fis.readLine()) != null) {
patternsToSkip.add(pattern); //단어분철
}
} catch (IOException ioe) {
System.err.println("Caught exception while parsing the cached file '"
+ StringUtils.stringifyException(ioe));
}
}
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String line = (caseSensitive) ?
value.toString() : value.toString().toLowerCase();
for (String pattern : patternsToSkip) {
line = line.replaceAll(pattern, "");
}
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
Counter counter = context.getCounter(CountersEnum.class.getName(),
CountersEnum.INPUT_WORDS.toString());
counter.increment(1);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
// a [1, 1, 1]
// b [1, 1]
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result); // a 3
}
}
public static void main(String[] args) throws Exception {
//1. hdfs 환경설정 파일 정보 세팅 확인
Configuration conf = new Configuration(); //core-site.xml
//2. main(String[] args) 실행 구문을 받아서 GenericOprionsParse를 통해 입력받은 구문을 확인한다.
GenericOptionsParser optionParser = new GenericOptionsParser(conf, args);
// 3. 실행 구문을 리턴 받아서 String[]로 리턴 (실행구문 -in, out)
String[] remainingArgs = optionParser.getRemainingArgs();
if ((remainingArgs.length != 2) && (remainingArgs.length != 4)) {
System.err.println("Usage: wordcount <in> <out> [-skip skipPatternFile]");
System.exit(2);
}
//4. 맞다면, 잡 실행 객체를 생성한다.
Job job = Job.getInstance(conf, "word count"); // (환경설정파일, job_name)
job.setJarByClass(WordCount2.class); //wc.jar 안에 main()을 가진 실행 클래스
job.setMapperClass(TokenizerMapper.class); //4-1. 맵 실행하는 클래스 : 파일의 내용을 읽어서 단어로 분철 후 1로만듬
/* ex) 아래와 같이 분철
* a 1
* python 1
* a 1
* hi 1
* python 1
* python 1
*/
job.setCombinerClass(IntSumReducer.class); //4-2. []리스트로 그룹핑과 정렬값 a[1,1], hi[1], python[1,1,1]
job.setReducerClass(IntSumReducer.class); //4-3, a 1, hi 1, python 3
// map 이 끝나야 Reducer 작업이 있고 사이에 combiner가 있다.
//5. MR작업이 끝나면 결과를 파일에 작성할 키와 밸류를 만들어서 실행
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
List<String> otherArgs = new ArrayList<String>();
for (int i=0; i < remainingArgs.length; ++i) {
if ("-skip".equals(remainingArgs[i])) {
job.addCacheFile(new Path(remainingArgs[++i]).toUri());
job.getConfiguration().setBoolean("wordcount.skip.patterns", true);
} else {
otherArgs.add(remainingArgs[i]);
}
}
FileInputFormat.addInputPath(job, new Path(otherArgs.get(0))); // /user/joe/wordcount/input /user/joe/wordcount/input
FileOutputFormat.setOutputPath(job, new Path(otherArgs.get(1))); // /user/joe/wordcount/input /user/joe/wordcount/output
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
HaDoop 폴더
/ → data 폴더 (권한주기)
home → hadoop → hadoop-2.10.1 → readme.txt : 읽어보자
→ bin
→ sbin (실행할 수 있는 파일이 들어있다 .sh 라는 확장자를 가짐)
해당 운영체제에서 정보, 라이브러리를 해당
→ etc → hadoop → xml(xml이 가지고있은 css형식스타일), sh(exe파일처럼 실행하는 파일)
log4j : 기록지 kms로 시작하는 4 개, 총 5개 한세트
marster, slave : 2개 한세트
map으로 시작하는 5개 한세트 ,
core-site.xml → 기본 지정되어있음, 기본속성값 // <value> host9000번호는 변경가능, 주석 참고해라 <Put-site~~~?>
hdfs.xml : namenode, datanode 는 무조건 값 줘야한다.
mapreduce : 매핑하는것만 줌
yarn-site.xml
꼭 이순서대로 값 줘라
Site-specific configuration - etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml.
반드시 봐야할것은 버전이 달라질때 꼭 아래 내용 확인 해라

잡트래커는 → 테스크트레커를 포함, 테스크트레커는 잡을포함
< env.sh >
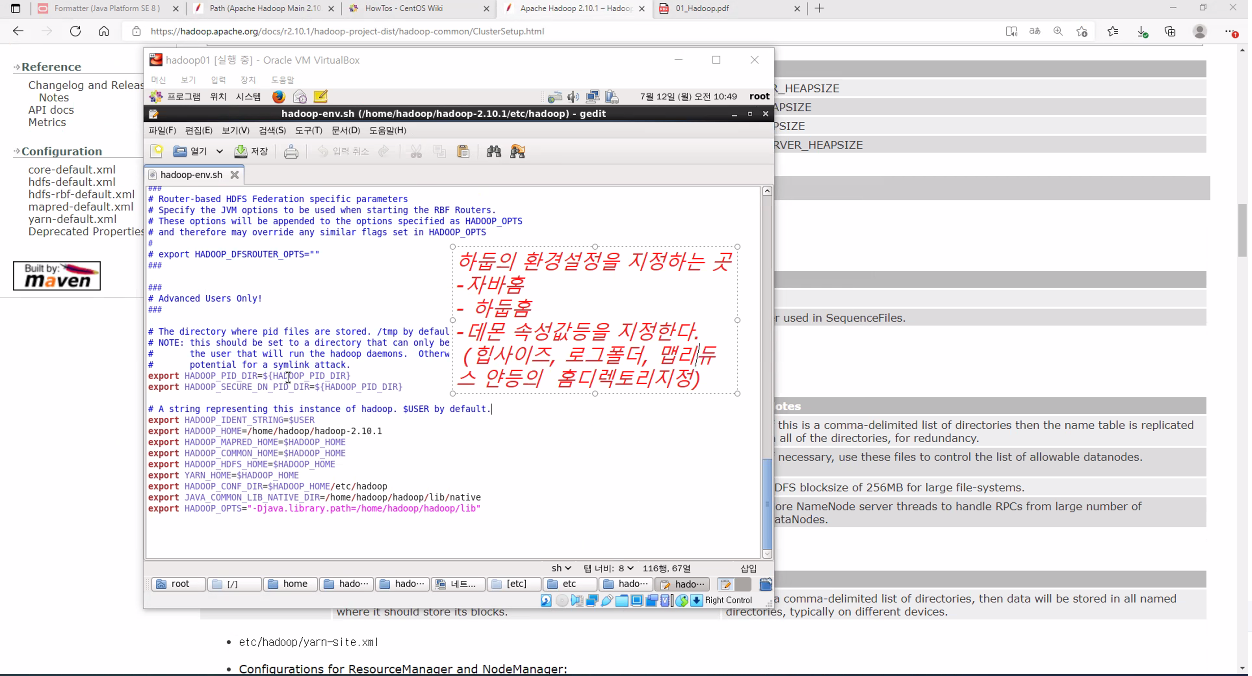
< hdfs.site.xml >
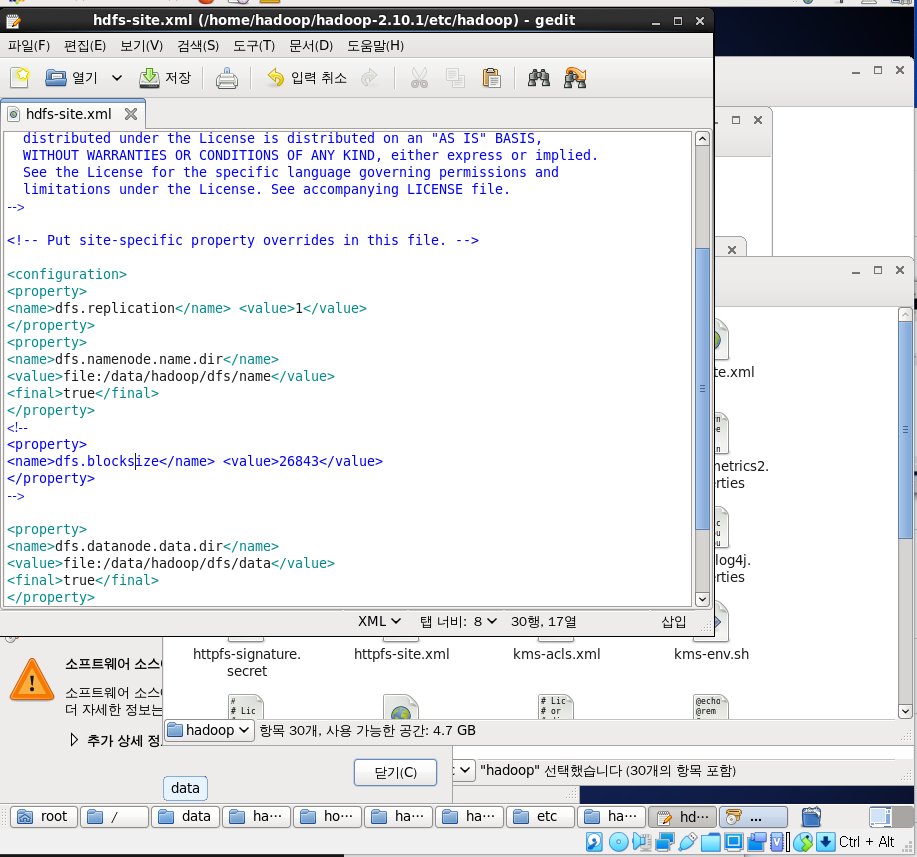
<hadoop 2.0 부터 Yarn 생김>

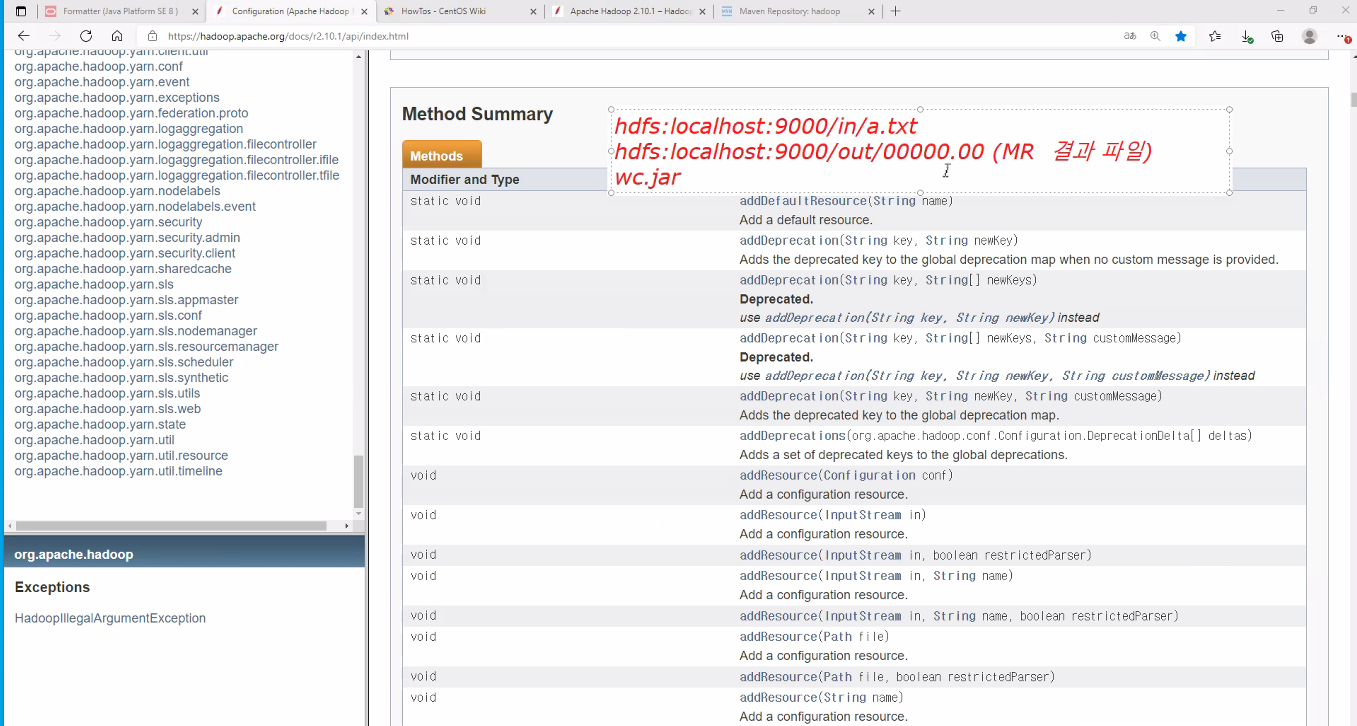
uml 로 상속관계를 보면 아래와 같다.
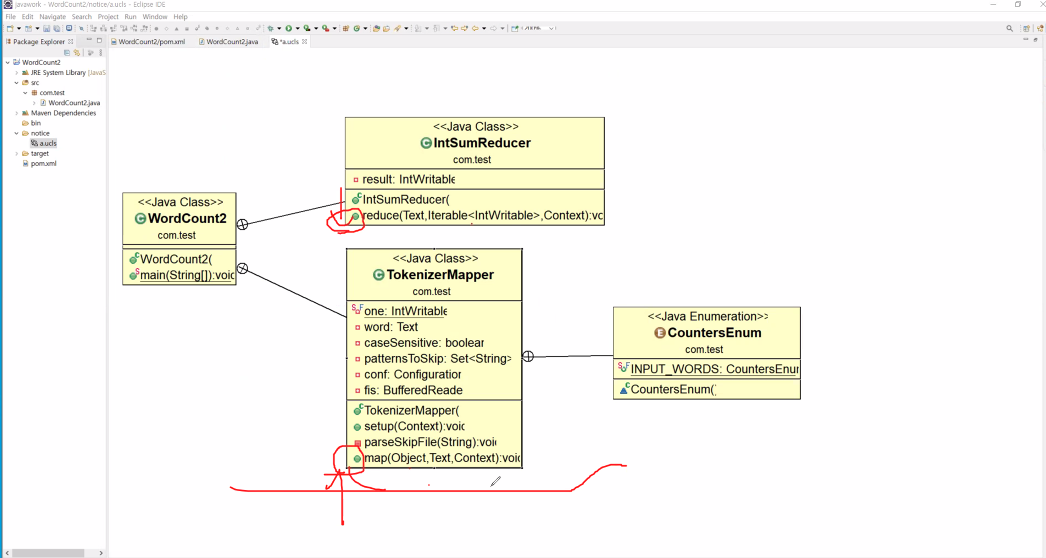
<Object, Text 는 input, Text, IntWritable은 output>

Hadoop ssh 실행

'|Playdata_study > HADOOP' 카테고리의 다른 글
| 210715_HADOOP(HDFS3 연결최종) (0) | 2021.07.15 |
|---|---|
| 210714_HADOOP (MapReduce 2) (0) | 2021.07.14 |
| 210713_HADOOP (HDFS Format) (0) | 2021.07.14 |
| 210709_HADOOP(설치 + Java설치) (0) | 2021.07.09 |
| 210708_HADOOP (개요) (0) | 2021.07.08 |



댓글