Linux 설치
1. 이클립스 → 오른쪽 마우스 클릭 → new → other → maven 있는지 확인

2. VM virtualBox 를 다운받는다.

https://www.virtualbox.org/wiki/Downloads
Downloads – Oracle VM VirtualBox
Download VirtualBox Here you will find links to VirtualBox binaries and its source code. VirtualBox binaries By downloading, you agree to the terms and conditions of the respective license. If you're looking for the latest VirtualBox 6.0 packages, see Virt
www.virtualbox.org
3. 새로만들기 → 이름 HADOOP01 → 종류 LINUX → 버전 Reahat(64-bit) → 다음

4. 메모리 크기 : 4098 정도로 늘린다 → 다음

5. 계속 다음을 누른다 → 마지막 메모리는 16GB로 늘린다.




6. 새로만들어진 HADOOP01 → 오른쪽 마우스 클릭 → 설정 → 저장소 → 컨트롤러IDE → 오른쪽, 광학 드라이브 →
IDE 프라이머리 마스터 → 디스크모양 → 가상 광학디스크 선택/만들기 → 전에 다운받았던 center os → 선택 → 확인
→ 하둡 더블클릭 → 실행




7. 다시 설정 → 일반 → 고급 → 클립보드, 드래그앤 드롭 → 양방향 → 확인

8. 설정 → 공유폴더 → 바탕화면에 폴더 만들기 (my hadoop) → 공유 추가 → 폴더경로 선택 → 폴더이름 myhadoop → 읽기전용, 자동마운트 체크 → 확인

9. 도구 → 환경설정 → 입력 → 가상머신 → 호스트키 조합 (아무거나) , 머신에서 마우스 빠져나오는것 설정

10. hadoop01 더블클릭하여 실행 후 바로 엔터 → 설치화면 나오면서 언어설정 → 한국어 →
→ 계속 엔터 → 기본저장 장치 → 다음 → 예 모든데이터를 삭제합니다. → 네트웤스 설정도 기본으로 하고 다음 →
아시아/서울 다음 → Root 암호 설정 → 확인 → 사용자 레이아웃? or 기존의 Linux 교체 다음 → 디스크에 변경사항 기록 → 사용자 계정 만들고 확인 → reboot


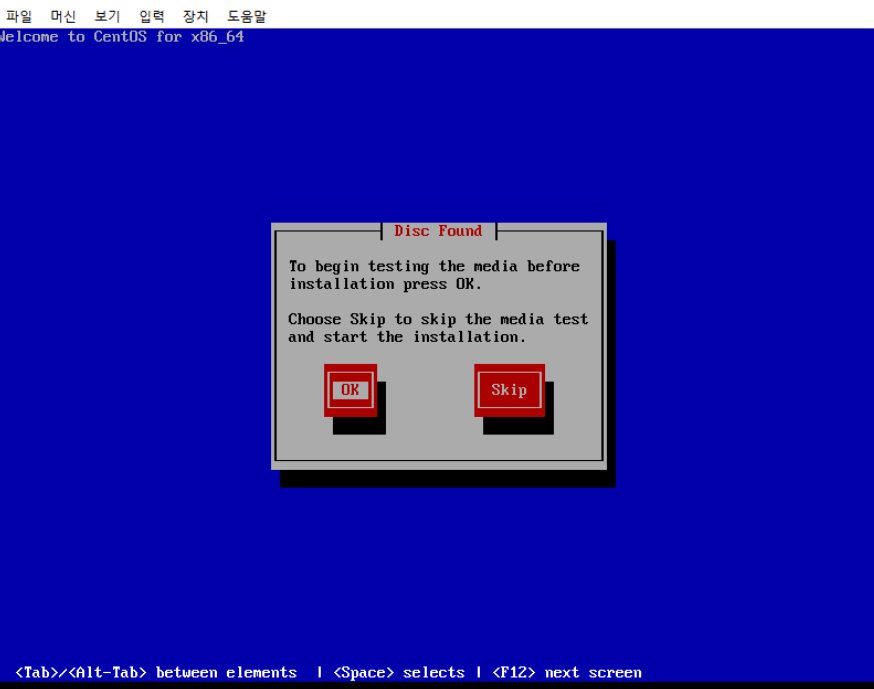

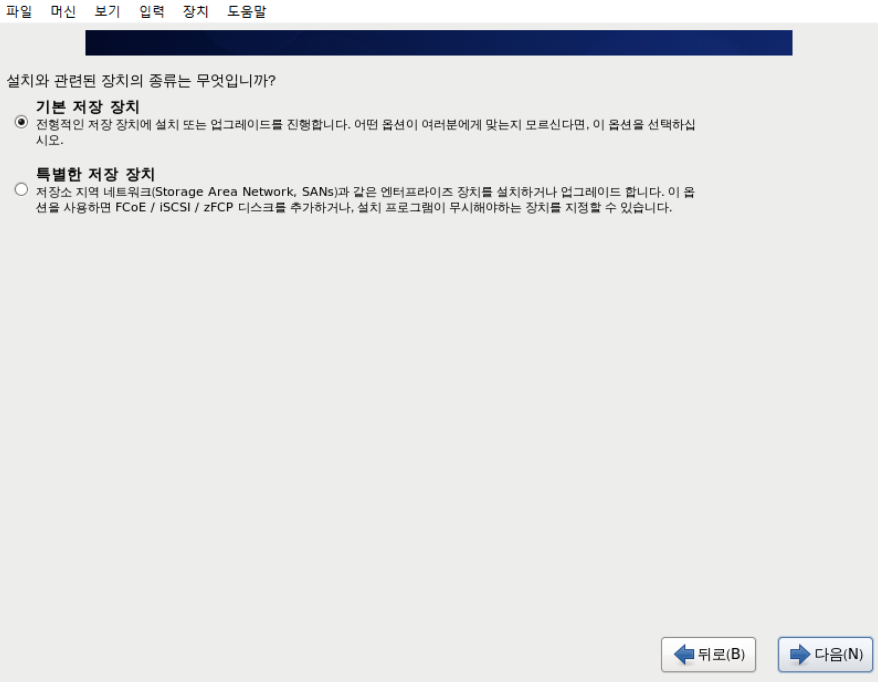



11. 그 이후 세컨더리 마스터에서 또 지정해준다.

LINUX 명령어 수행
1. yum 을 이용해 컴파일러 GCC를 설치해 보자.
yum(yellowdog Updater Modified)?
rpm기반의 시스템(Redhat계열)을 위한 자동 업데이터이자 패키지 설치/제거 도구
- 업데이트목록확인 : yum check-update
- 추가된 패키지목록 : yum list [installed]
- 업데이트 : yum update [패키지명1] [패키지명2....]
- 제거 : yum remove [패키지명1] [패키지명2....]
1.
yum clean all
2.
echo "https://vault.centos.org/6.10/os/x86_64/" > /var/cache/yum/x86_64/6/base/mirrorlist.txt
echo "https://vault.centos.org/6.10/extras/x86_64/" > /var/cache/yum/x86_64/6/extras/mirrorlist.txt
echo "https://vault.centos.org/6.10/updates/x86_64/" > /var/cache/yum/x86_64/6/updates/mirrorlist.txt
3.
yum install update
4.
yum install kernel*
5.
yum install gcc
6.
게스트 cd 설치(gas cd 오마클 자동으로실행)
7.
reboot
2. 리눅스에서 명령을 확인할 때는 man이라는 명령을 사용한다.
도움말 보기 : man --help
[root@hadoop01 바탕화면]# man --help
man, version 1.6f
usage: man [-adfhktwW] [section] [-M path] [-P pager] [-S list]
[-m system] [-p string] name ...
a : find all matching entries
c : do not use cat file
d : print gobs of debugging information
D : as for -d, but also display the pages
f : same as whatis(1)
F : format only - do not display
h : print this help message
k : same as apropos(1)
K : search for a string in all pages
t : use troff to format pages for printing
w : print location of man page(s) that would be displayed
(if no name given: print directories that would be searched)
W : as for -w, but display filenames only
C file : use `file' as configuration file
M path : set search path for manual pages to `path'
P pager : use program `pager' to display pages
S list : colon separated section list
B browser : use program `browser' to display HTML files
H pager : use program `pager' to render HTML files as text
m system : search for alternate system's man pages
p string : string tells which preprocessors to run
e - [n]eqn(1) p - pic(1) t - tbl(1)
g - grap(1) r - refer(1) v - vgrind(1)
# which yum : 위치 찾기
[root@hadoop01 바탕화면]# which yum
/usr/bin/yum
--k: 모든 내용검색
--w: 페이지 검색
--s: 섹션 검색
# man ls : 경로내용 나열, 목록보기
# man man : 가이드
3. etc 파일을 살펴보자.
/ 밑에있는 애들은 손대지 않는다!
.sh : 실행파일 (exe. 배치파일처럼)
bashrc, environment, profile : 전역변수 설치
데스크탑이면 전역변수 걸지마라 (무한루프 돈다)
설치 된 파일을 찾고싶을 때
( java.exe는 어디 어디 있어?)
[hadoop01@localhost user]$ whereis java
[root@hadoop01 바탕화면]# whereis java
java: /usr/bin/java /etc/java /usr/lib/java /usr/share/java /usr/share/man/man1/java.1
실행 파일을 찾고 싶을 때
(전역패스로 지정된 실행파일 위치 - java.exe는 어디서 실행되니?)
[hadoop01@localhost user]$ which java
[root@hadoop01 바탕화면]# which java
/usr/bin/java
리눅스의 설정 파일
1. /etc/environment 파일에서 명령을 실행하여 시스템 환경을 설정한 후 ./etc/profile 파일에 있는 명령을 평가한다.
2. 사용자의 홈 디렉토리에 .profile 파일이 있는지 확인 .
profile 파일이 있다면 시스템은 이 파일을 실행하면 환경 파일의 존재 여부를 작성한다.
즉 (일반적으로 .env인) 환경 파일이 있으면, 시스템은 이 파일을 실행하고 사용자 환경 변수를 설정한다.
3. /etc/environment/etc/profile 및 .profile 파일은 로그인 시 한번만 실행 되지만 .env파일은 사용자가 새로운 쉘이나 창을 열때마다 실행된다.
4. /etc/environment : 모든 프로세스에 대해 기본 환경을 지정하는 변수를 정의한다.
로그인시 .profile이라는 로그인 프로파일을 읽기전에 시스템은 /etc/environment 파일에서 환경 변수를 설정한다.
5. /etc/profile 파일 : 시스템 관리자만이 수정할 수 있으며, 시스템 차원의 default 변수를 제어한다.
(변수 반출/ 파일작성 마스크(umask) / 터미널 유형/ 새로운 메일이 도착했음을 알리는 메일 메시지/ 시스템 관리자는 모든 사용자가 사용하는 환경 변수등을 /etc/profile 파일에 작성한다.
6. 사용자 홈 디렉터리에 존재하며 이 파일을 통해 사용자 개인의 작업 환경을 조정할 수 있다.
.profile 파일이 있으면 이 파일의 명령이 실행된다.
7. .env 파일을 통해 사용자 개인의 작업 환경 변수를 조정할 수 있다.
사용자는 .env 파일을 수정하여 원하는 사용자 환경 변수를 지정할 수 있다.
디렉토리 명령
pwd: 현재 위치 경로를 리턴
cd : 디렉토리 이동
cd .. : 상위 디렉토리
cd ~ : 자신의 홈 디렉토리
cd ~[사용자명]: 사용자 명의 홈 디렉토리로 이동
ls : 목록보기
ls -al : 숨김파일을 포함해서 자세히 출력한다.
mkdir[디렉토리명] : 디렉토리생성
rmdir : 디렉토리삭제
rmdir -p : 상위 경로까지 삭제
rmdir -r 디렉토리명 : 하위 까지 삭제
ex01) hadoop01의 홈 디렉토리로 이동해보자. test파일도 만들자
- 루트계정에서
[root@localhost 바탕화면]# cd ~ hadoop01
[root@localhost hadoop01]# pwd
/home/hadoop01
[root@localhost hadoop01]# mkdir test
[root@localhost hadoop01]# cd /home/hadoop01/test/
[root@localhost 바탕화면]# cd ~ hadoop01
[root@localhost hadoop01]# pwd
/home/hadoop01
[root@localhost hadoop01]# mkdir test
[root@localhost hadoop01]# cd /home/hadoop01/test/
파일 관련 명령
touch [파일명] : 파일생성 - man touch
cp [원본][사본] : 복사본 man cp
mv[원본][대상지] man mv
rm 파일명 : 파일삭제 man rm
rm -rf 파일/디렉토리 : 파일은 그냥 삭제, 디렉토리일 경우에는 하위의 파일까지 모두 지운다.
cat[파일] : 파일 내용을 출력한다.
ex02) /home/hadoop01/test에서 myfile.txt라는 파일을 생성하자.
[root@localhost test]# touch myfile.txt
ex03) test목록을 확인하자.
[root@localhost test]# ls
ex04) /home/hadoop01/test02 폴더를 만들자.
[root@localhost test]# mkdir ~hadoop01/test02
ex05) myfile.txt를 test02로 myres.txt로 복사하자.
[root@localhost test]# cp ~hadoop01/test/myfile.txt ~hadoop01/test02/myres.txt
ex06) myres.txt test폴더로 이동하자.
[root@localhost test02]# mv ~hadoop01/test02/myres.txt ~hadoop01/test/
ex07) test폴더를 파일 포함 삭제하자.
[root@localhost test02]# rm -rf ~hadoop01/test/
ex08) test02/myfile.txt만 삭제하자.
[root@localhost test02] rm ~hadoop01.test02/myfile.txt'?y
rm : remove 일반 빈파일 '/home/hadoop01/test02/myfile.txt'?y
ex09) 파일을 생성해보자.
[root@localhost test02] # touch a.txt, b.txt
[root@localhost test02] #ls ~al //,로 사용하면 탐색 불가하다
😎
[명령어] > [파일] : 명령어의 출력을 파일에 저장한다. 덮어쓴다.
[명령어] >> [파일] : 명령어의 출력을 파일에 저장한다 추가한다.
[명령어] < [파일] : 파일에서 표준 입력받는다.
# 예제를 실행해 보자.
1. 파일을 생성해보자
cat>b.txt
abcde
abcde
[root@hadoop01 ~]# cat>b.txt
abcde
abcde
빠져나오기 ctrl+d
2. 확인해보자.
cat b.txt
[root@hadoop01 ~]# cat b.txt
abcde
abcde
3. 데이터 추가해보자
cat >>b.txt
aaaaabbbbb
[root@hadoop01 ~]# cat >> b.txt
aaaabbbb
[root@hadoop01 ~]# cat b.txt
abcde
abcde
aaaabbbb
4. 설정파일을 하나 열어보자.
cat /etc/passwd
[root@hadoop01 ~]# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
rtkit:x:499:499:RealtimeKit:/proc:/sbin/nologin
avahi-autoipd:x:170:170:Avahi IPv4LL Stack:/var/lib/avahi-autoipd:/sbin/nologin
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
abrt:x:173:173::/etc/abrt:/sbin/nologin
rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
haldaemon:x:68:68:HAL daemon:/:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
apache:x:48:48:Apache:/var/www:/sbin/nologin
saslauth:x:498:76:Saslauthd user:/var/empty/saslauth:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
gdm:x:42:42::/var/lib/gdm:/sbin/nologin
pulse:x:497:496:PulseAudio System Daemon:/var/run/pulse:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
vboxadd:x:496:1::/var/run/vboxadd:/bin/false
hadoop:x:501:501:hadoop:/home/hadoop:/bin/bash
[root@hadoop01 ~]#
5. grep 명령과 옵션을 찾아보자.
cat /etc/passwd | grep hadoop01
6. yum list | grep jdk,ps
grep : 파일 또는 입력 값 내에서 특정 패턴을 검색할 때 사용한다.
[root@hadoop01 ~]# yum list | grep jdk,ps
https://vault.centos.org/6.10/os/x86_64/repodata/repomd.xml: [Errno 14] PYCURL ERROR 6 - "Couldn't resolve host 'vault.centos.org'"
Trying other mirror.
https://vault.centos.org/6.10/extras/x86_64/repodata/repomd.xml: [Errno 14] PYCURL ERROR 6 - "Couldn't resolve host 'vault.centos.org'"
Trying other mirror.
https://vault.centos.org/6.10/updates/x86_64/repodata/repomd.xml: [Errno 14] PYCURL ERROR 6 - "Couldn't resolve host 'vault.centos.org'"
Trying other mirror.
😎새 계정 생성
시스템 → 관리 → 사용자 및 그룹 → 사용자 추가
find : 현재 디렉토리에 있는 목록을 보여준다.
find / -name *linux* : linux가 파일명에 포함된 모든 파일을 찾아준다.
find / -user linux : 소유자가 linux인 파일을 찾아준다.
find / -perm 755 : 퍼미션이 755인 애를 찾아준다.
7. hadoop01 인 소유자가 가진 파일을 찾아라.
find / -user hadoop01
8. grep 의 옵션
A 숫자 : 지정숫자 아래
B 숫자 : 지정숫자 위
C : 라인포함
i : 대소문자무시
n : 라인번호 출력
cat은 파일 안에 내용을 작성할 때 사용한다.
cat > mytest
1. apple
2. strawberry
3. watermelon
4. mandarin
5. pear
6. apricot
[root@hadoop01 ~]# cat > mytest
1.apple
2.strawberry
3.watermelon
4.mandarin
5.pear
6.apricot
[root@hadoop01 ~]# cat mytest
1.apple
2.strawberry
3.watermelon
4.mandarin
5.pear
6.apricot
9. 귤을 포함한 아래 2개의 과일을 찾아라
grep -A 2 mandarin mytest
[root@hadoop01 ~]# grep -A 2 mandarin mytest
4.mandarin
5.pear
6.apricot
10. 수박을 포함한 위 1 개의 과일을 찾아라
[root@hadoop01 ~]# grep -B 1 watermelon mytest
2.strawberry
3.watermelon
11. r자가 들어간 과일을 찾아라
[root@hadoop01 ~]# grep -i r mytest
2.strawberry
3.watermelon
4.mandarin
5.pear
6.apricot
12. s가 들어간 과일을 찾아라
[root@hadoop01 ~]# grep -i s mytest
2.strawberry
13. 과일 철자를 기준으로 정렬해라 sort
[root@hadoop01 ~]# sort -t"." -k 2 mytest
1.apple
6.apricot
4.mandarin
5.pear
2.strawberry
3.watermelon
14. 숫자를 기준으로 역순으로 정렬해라
[root@hadoop01 ~]# sort -r mytest
6.apricot
5.pear
4.mandarin
3.watermelon
2.strawberry
1.apple
댓글